A Story of a One-Line Bug Fix
It’s been a while since I’ve come across anybody brave and stupid enough to actually measure value of software in lines of code, but like any executive friendly metric, this idea keeps coming back in new forms with various degrees of disconnection from reality.
- Linux Kernel counts its lines.
- OpenStack made a fetish out of it.
- Ceph has spent enough time courting OpenStack to pick up the habit, too.
So after spending a couple of weekends chasing down a particularly annoying bug, and ending up with half a line of a fix, I thought that the story of my investigation and the diagrams I had to draw to navigate the seedy corners of the Samizdat stack might have some value not only as an instruction for past and future contributors, but also as an illustration of limitations of the COCOMO model.
What made that bug most annoying was how hard it was to reproduce. I’ve seen it happen in production on heavily loaded Samizdat sites since around 2011, but until recently, wasn’t able to come up with a synthetic load that would allow me to catch it in a controlled environment. All I had was the following stack trace that would occasionally show up in the logs, indicating that somebody somewhere got a 500 instead of RSS:
Samizdat: 2016-02-21 11:00:42 -0800: RuntimeError: Template not found: 'frontpage.rhtml'
Error ID: ac1236189d83134ea56b95f973c49c99
Site: samizdat
Route: /frontpage/rss
CGI parameters: {"feed"=>"updates"}
Backtrace:
/usr/lib/ruby/vendor_ruby/samizdat/engine/view.rb:21:in `initialize'
/usr/lib/ruby/vendor_ruby/samizdat/engine/view.rb:34:in `new'
/usr/lib/ruby/vendor_ruby/samizdat/engine/view.rb:34:in `block in cached'
/usr/lib/ruby/vendor_ruby/syncache/syncache.rb:177:in `fetch_or_add'
/usr/lib/ruby/vendor_ruby/samizdat/engine/site.rb:217:in `fetch_or_add'
/usr/lib/ruby/vendor_ruby/samizdat/engine/view.rb:33:in `cached'
/usr/lib/ruby/vendor_ruby/samizdat/engine/controller.rb:63:in `render_template'
/usr/lib/ruby/vendor_ruby/samizdat/engine/controller.rb:40:in `render'
/usr/lib/ruby/vendor_ruby/samizdat/engine/request.rb:381:in `response'
/usr/lib/ruby/vendor_ruby/samizdat/engine/dispatcher.rb:128:in `render'
/usr/lib/ruby/vendor_ruby/samizdat/engine/dispatcher.rb:115:in `call'
Of course there’s no “frontpage.rhtml” anywhere in Samizdat, and what’s an RSS feed generator doing with an HTML template anyway?
Back in 2011, I gave the Controller class a long hard stare, but nothing obvious popped up. With no obvious mistakes in the code, and no way to reproduce, I was left with the loathsome option to blindly tweak things around until the bug disappeared on its own.
Around the same time, I lost interest in Samizdat due to some personal and some not so personal reasons, and, since the bug wasn’t exactly a showstopper, I left it alone until this February, when Brendan Gregg’s “Systems Performance” has inspired me to get back to load testing Samizdat.
After some research I’ve settled on Siege.
It is free, small, simple, is packaged for Debian (with extra points for not having a gazillion of dependencies), can log into the site and keep track of its cookies, and doesn’t force you to wade through megabytes of XML or learn yet another configuration language. Turns out that Siege can’t get past the cross-site request forgery protection I’ve introduced in 2010, so it can’t quite replace the Samizdat’s functional test (tc_robot.rb) just yet. Oh well, you can’t have everything.
So I’ve populated siege-urls.txt with a diverse cross-section of Samizdat’s read-only pages:
PROTO=http
SITE=samizdat
$(PROTO)://$(SITE)/
$(PROTO)://$(SITE)/tags
$(PROTO)://$(SITE)/moderation
$(PROTO)://$(SITE)/frontpage/updates?page=2
$(PROTO)://$(SITE)/blog/siege
$(PROTO)://$(SITE)/frontpage/rss
$(PROTO)://$(SITE)/frontpage/rss?feed=updates
and told it to login with the user that I’ve created for it:
login-url = http://samizdat/member/login POST login=siege&password=siege
With that in siegerc, I’ve launched it in the load test mode:
siege -c10 -i -t10M -q -Rsiegerc -fsiege-urls.txt
with tc_robot.rb looping in the background to keep posting new content and flushing the cache in syncache-drb:
while true; do ruby -I. test/tc_robot.rb; done
Before I got to the profiling and optimizing part of the excercise, the elusive “Template not found” error started showing up in the logs. Aha, I have you now!
The top half of that stack trace has no incriminating evidence: View class is duly trying to initialize from the template name it’s given, the problem is that for some reason Controller is asking for a template that doesn’t exist, in a situation where template shouldn’t even be involved.
According to the stack trace, the trouble starts with the very first line in Controller#render():
@content_for_layout ||= render_template(@template)
At least that explains where “frontpage.rhtml” is coming from: @template is populated with this value by default_template(). But why is render_template() called at all?
To refresh my memory about entry points into the Controller class, I’ve put together a simple sequence diagram:

A Controller instance is created by Route, that’s when we get the default inner template and outer layout names defined. Based on the ‘/frontpage’ part of the route in the error log, that’s FrontpageController, which doesn’t interfere with parent’s initialize(), so at this point these template names are still set.
Then Dispatcher calls an action method, once again based on the route. In this case, that’s FrontpageController#rss(), which relies on ApplicationHelper#feed_page() to convert the data it pulls from the UpdatesList dataset into RSS and to set the Controller instance variables up in a way that’s supposed to prevent render_template() from ever being called.
Apparently, something somewhere along this code path goes wrong, because @contents_for_layout either remains nil, or gets unset before we get to render(). Time to draw a more detailed sequence diagram and check it for plot holes:
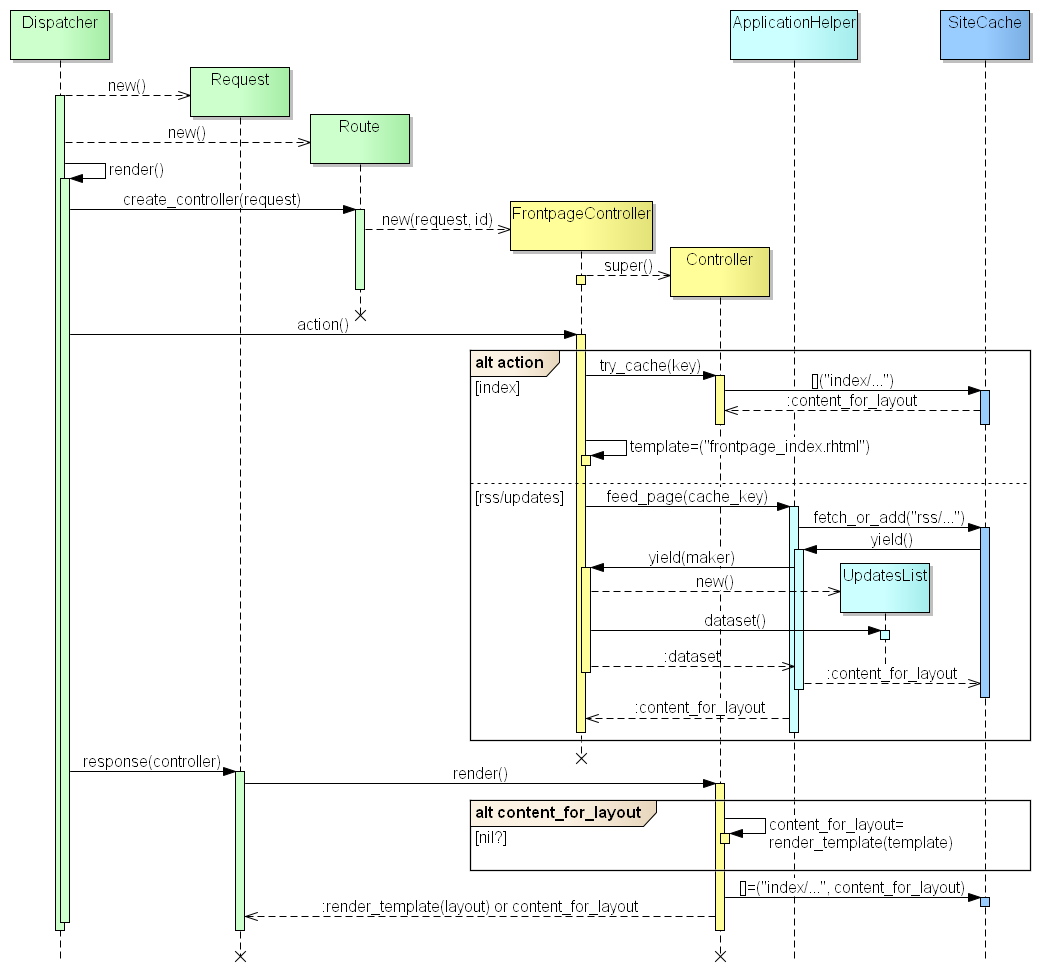
Nope, no plot holes. The only way for @content_for_layout to be nil is for SiteCache#fetch_or_add() to return nil, but the whole point of fetch_or_add() is to always return the result of the block it’s given (regardless whether it ends up being executed by this cache client or by another). And the block it’s given ends with to_s, so it would always return a String.
Now that I can reproduce the bug, checking if fetch_or_add can return a nil for something it’s not supposed to is as simple as one line of debug output. Sure enough, just before the “Template not found” error, I got:
Samizdat: nil value returned for cache key 'rss/http://samizdat/frontpage/updates/en'
So it was SynCache’s fault all along. Makes sense: the fact that the bug only reproduces intermittently under high load points at a race condition, and the shared cache is where all the Samizdat threads and processes meet and get the most chances to race against one another.
The problem with that theory is, SynCache#fetch_or_add() is simple as a doorknob:
def fetch_or_add(key)
debug { 'fetch_or_add ' << key.to_s }
entry = get_locked_entry(key)
begin
if entry.value.nil?
entry.value = yield
end
return entry.value
ensure
entry.sync.unlock
end
end
It just yields the value from the block and returns it. That’s it.
Except that Samizdat isn’t using SynCache directly. Yielding complex blocks across a DRuby connection turned out to be as unreliable as it sounds, so back in 2011 I’ve introduced a RemoteCache client-side wrapper that locks an entry in remote cache with a blank placeholder before yielding the block locally in the client process.
RemoteCache#fetch_or_add() is not that trivial, and has different code paths for 4 cases:
- the value is already in the cache, we just return it;
- we get there first, yield the block, write the result to remote cache, and return it;
- we find another client’s placeholder, we wait until they’re done, and then retrieve and return the value;
- we find another client’s placeholder, we wait and time out, we replace their placeholder with ours, yield the block, write and return the result.
Another couple of debug statements later I found out that the bug is always triggered by the case #3, waiting for and retrieving a value placed by another client.
With the bug cornered into a narrow code path, it was time for a timing diagram, enumerating all state transitions that can happen during this sequence. Lets see if there’s a combination that can trick RemoteCache#fetch_or_add() into returning a nil:
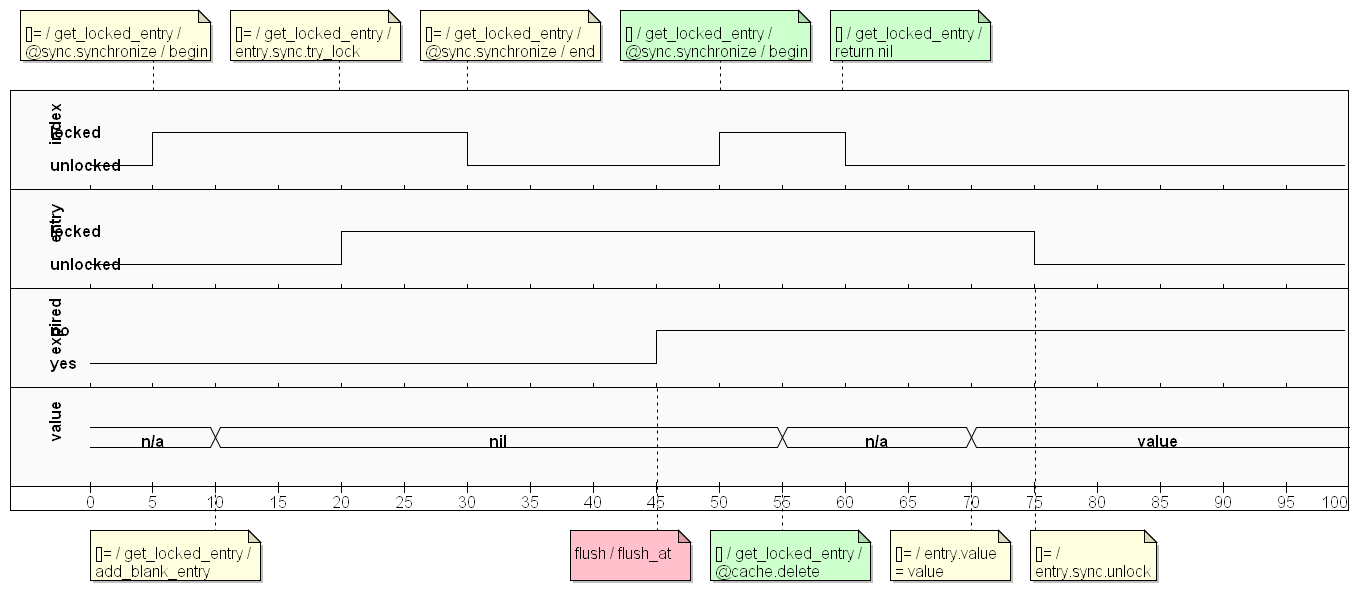
And here it is:
- other client’s write ("[]=") locks the cache index;
- other client’s write creates a blank entry (with value = nil);
- other client’s write locks the entry;
- other client’s write unlocks the cache index;
- the entry gets expired by a third client’s delayed flush (“flush_at”);
- this client’s read ("[]") locks the cache index;
- this client’s read deletes the expired entry and returns nil.
It’s perfectly reasonable for a read to return nil for a key that doesn’t exist in the cache, and just as reasonable to pretend that the key doesn’t exist if the corresponding entry has expired. But RemoteCache#fetch_or_add() did not account for the possibility that other client’s placeholder will not necessarily get replaced by real value and can simply disappear.
With the root cause finally clear, the solution was obvious: if the other client’s placeholder is no longer there, we’re back to doing the work ourselves. In the code, all it takes is add the “value.nil?” check to entry conditions for case #4:
https://github.com/angdraug/syncache/commit/2cb3948
Another run of the same load test confirmed that this was it: the number of errors reported by Siege went from 0.1% down to 0.
At three whole words, this is not the shortest one-line bug fix ever, I’ve seen one-character fixes for similar bugs. At a couple of weekends spent on a simple test script and a few diagrams, it’s far from the most expensive, too. The scary part of this story is how typical this experience is, and how little tangible evidence is left of the efforts spent on these one-line fixes. Some lines of code are so much more equal than others that it makes me question the whole idea of counting them. All the SLOC count tells you is how much code you’ll have to read and comprehend to come up with your next one-line bug fix.